The bias-variance tradeoff
Karen Tao, UX Researcher
July 22, 2020

Photo by Marc A
In my last blog post, we introduced overfitting and underfitting in machine learning. Now we will build upon that foundation and discuss variance error and bias error, and what data scientists mean by the “bias-variance tradeoff.”
Recall from introductory statistics that variance measures how far off from the average a data point is. It describes how spread out, or “varied” a dataset is. When we train a machine learning model to make predictions, variance error can tell us how inconsistent our predictions are from one another, or how spread out our predictions are. Models with high variance give scattered predictions as the model is fitted too much to capture all the data points in the training data. High variance is therefore common for overfitted models, when the model performs well on the training set but does not do well on the test set (refresher on training set and test set). Think of the overfitted model as being extremely flexible and fits itself perfectly to the data points of the training set. When this model encounters a data point from the test set, it is now incapable of making the right prediction.
On the other hand, we have bias error. For example, I have a biased opinion about fry sauce because ketchup and mayo together is just perfect to dip my fries in. In fact, I insist on having fry sauce for my fries. That is a bias. I would always choose this option over anything else, regardless of the circumstances such as where I am eating. In machine learning, models with high bias pay very little attention to the training data and oversimplify the model. This results in poor performance on both the training and test data, which is representative of underfitted models. The model makes the same prediction consistently regardless of the specifics of the data points it encounters. This results in an inflexible model.
Imagine you are throwing darts with some friends. Below is an illustration of how four different players may throw.
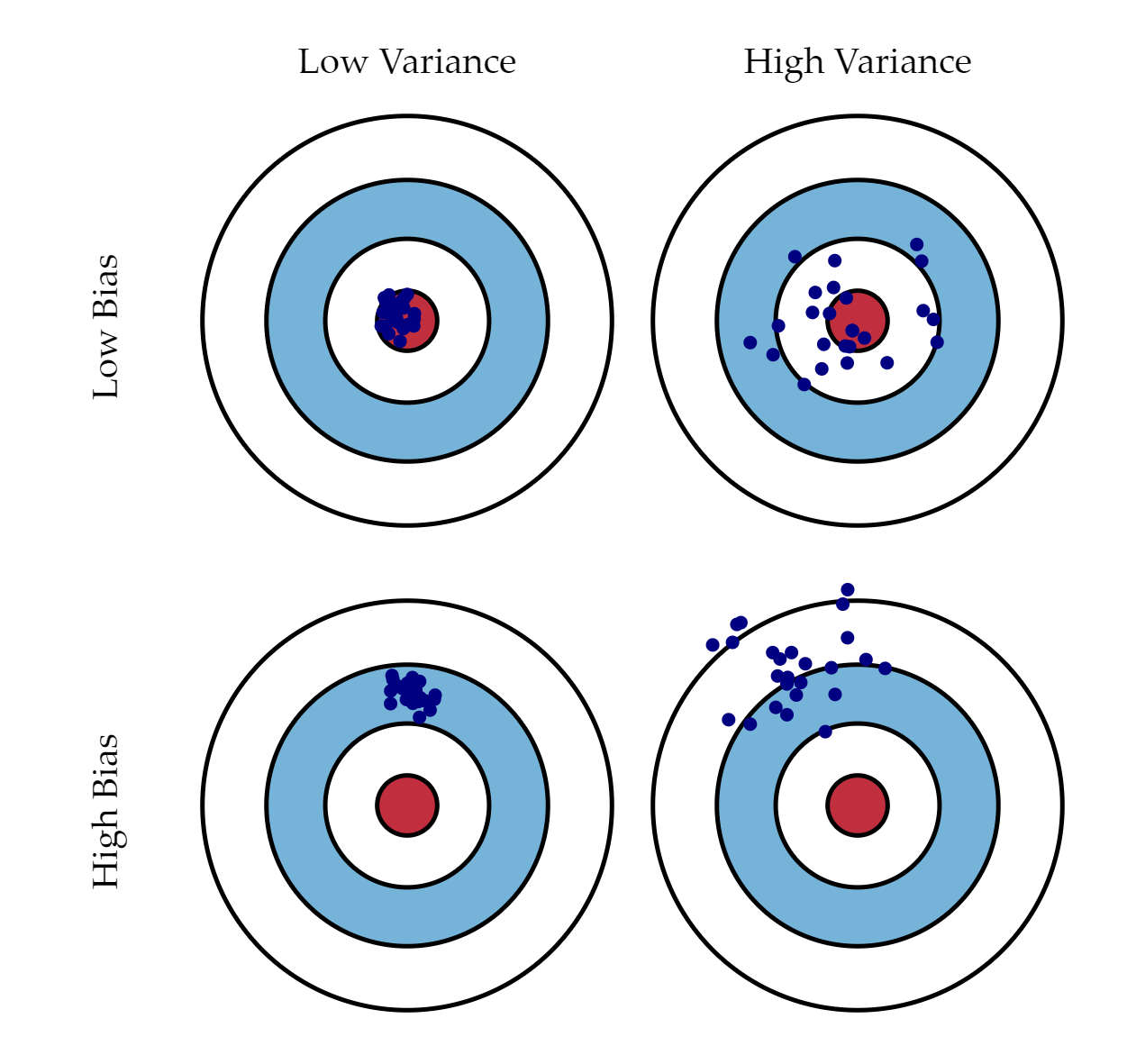
Notice that players with high variances tend to throw all over the place, while players with high bias tend to throw consistently in the same direction but not necessarily hitting bullseye.
In machine learning, the goal is to select the model that has low bias and low variance, as demonstrated by our dart players. Models that are too complex tend to have high variance and low bias, as they have adapted too well to the data points. They are flexible. Models that are too simple tend to have high bias and low variance. These are not flexible enough. The bias-variance tradeoff refers to choosing the model that is flexible enough--not too simple, yet not too complex, with the goal to have low variance error as well as low bias error.
If you are like me and prefer mathematical equations to words, here is an excellent resource for the mathematical definition. I highly encourage you to dig into those equations to solidify your understanding on this complex topic, while having some fries with fry sauce… maybe?