How accurate is your machine learning model?
Karen Tao, Researcher
December 30, 2020

'Tis the season to buy gifts for my niece, who receives multiple gifts from each of her uncles and aunts. Let's pretend I will build a machine learning model to predict whether she likes a gift because we all know how important it is to be the favorite aunt who also happens to be a data nerd. Assuming I have meticulously collected data of past gifts she received and whether she liked any particular present, we can build a supervised machine learning model.
More specifically, this will be a classification model. Our labels or outputs are binary—she either liked a gift or not. Each gift's features or attributes may include whether it lights up, the gift wrap that it came in, whether it makes noises, whether it is squishy, or whether it is edible. There could be other variables as well, such as whether her parents approve of the gift. Consideration for all variables is essential because missing a crucial variable could result in a machine learning model that is not accurate. But how do we define accuracy?
The obvious choice may appear to be accuracy, defined as the number of correct classifications as a portion of total gifts received. For example, let's say my niece received 100 gifts, and our model correctly predicted 98 outcomes of whether she liked the gift or not. Doesn't that sound like a decent model? Well, what if she disliked most of her gifts? Like a good two-year-old, she says "No" to everything. Our model had learned to predict "No" regardless of the features of the gift. Accuracy may not be the best choice, after all.
If the output labels are imbalanced, as in the case of the two-year-old who rejects everything, using simple accuracy may produce an overly optimistic evaluation. Fast forward a few years, and my adorable niece now is liking some gifts she receives. With the new data, I can build a new model and look at the confusion matrix, as in Figure 1, to see how my updated model performs. The total number of gifts in our dataset has now grown to 200.
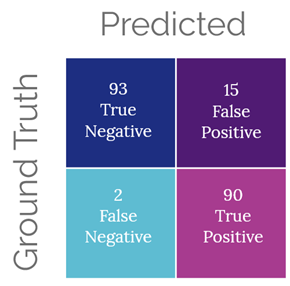
Within Figure 1, the upper left quadrant indicates the number of times our model predicted "No," and the ground truth is that my niece did not like a gift. The lower left shows the number of times our model predicted "No" while she actually liked a gift. The upper right indicates the number of times the model predicted "Yes," and she did not like a gift. The lower right shows incidences when the model correctly predicted that she liked a gift.
Now we can calculate the precision and recall of our model. Precision is the fraction of true positives among all of the gifts which were predicted to be liked. In our case, this would be 90 (true positive) out of 105 (true positive and false positives). Recall is the fraction of true positives among all the ground truth positives. In our example, this would be 90 (true positive) out of 92 (true positive and false negative). Precision is sometimes also called positive predictive value as it corresponds to the actual cases predicted to be true as a percentage of all that were predicted to be true. Recall is also called sensitivity as it corresponds to the model's ability to make correct predictions of true positives out of all cases that are ground truth positives.
Furthermore, the F1 score is often used as a measure derived from precision and recall to evaluate model performance. When there is an imbalance in the output labels, the F1 score is a better metric than accuracy as it also reflects how sensitive the model is to ground truth positive. Ultimately, these are all ways to measure how well a model is performing. Data scientists should leverage domain knowledge to select which of these measures to use. For example, do we want to penalize false positives tests in a pandemic? People who don't have the virus get sent home to rest. Or do we care more about the false negatives who test negative but actually can spread the virus?
Understanding the basics behind accuracy metrics can help us interpret some medical jargon, but it can also make us better consumers of the news. Stay well and have a joyous holiday season. I'd better hurry and finish wrapping gifts for my niece.